SocNetV v1.6 Released with a Working Web Crawler
The SocNetV project has just released its latest version 1.6. Binaries for Windows, Mac OS X, and Linux are available from the Downloads menu.
Revamped Web Crawler
The new version brings back the web crawler feature, which had been disabled in the 1.x series so far.
To start the web crawler:
- Go to
Network -> Web Crawleror pressShift+C.
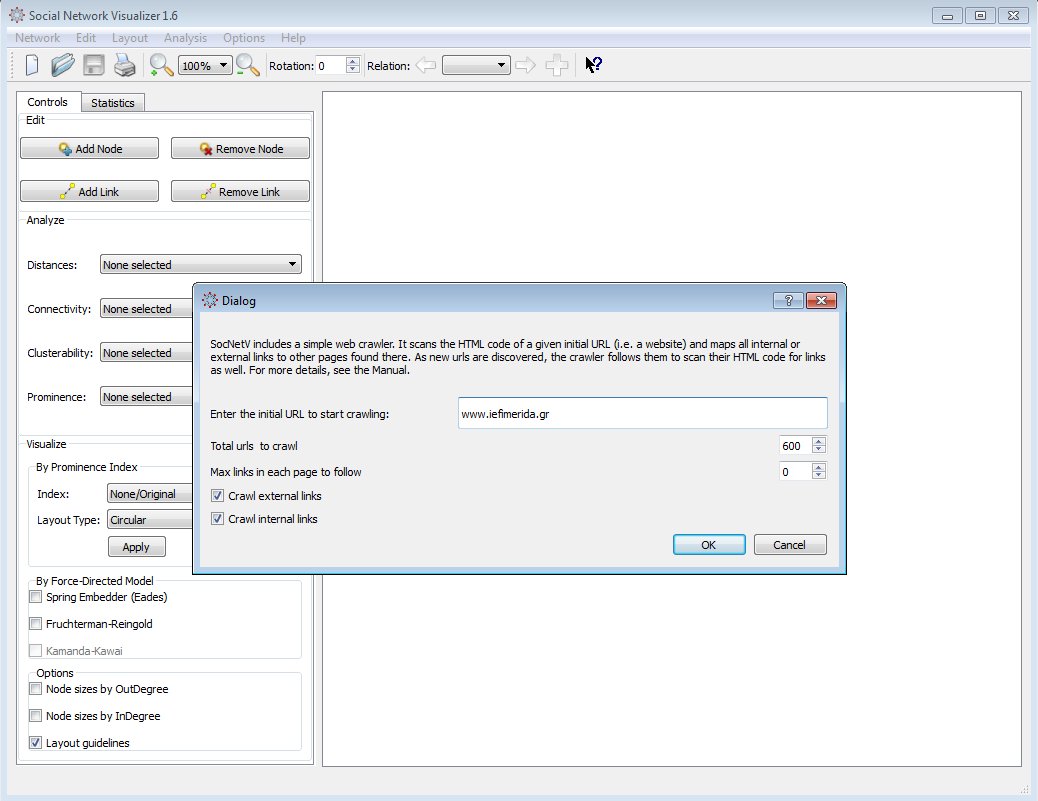
A dialog will appear where you:
- Enter the initial web page (seed).
- Set the maximum number of nodes/pages (default is 600).
- Choose the types of links to crawl: internal, external, or both. By default, the crawler processes both.
How It Works
The new web crawler is significantly improved compared to the 0.x releases. It consists of two components:
- Spider: Visits the specified initial URL, downloads its HTML, and processes it.
- Parser: Scans the downloaded HTML for
hreflinks to internal or external pages and adds them to a queue of URLs (the “frontier”).
The spider and parser run on separate threads, ensuring faster execution.
As URLs are added to the queue, the spider visits them, downloads their HTML, and the parser extracts more links, continuing the cycle.
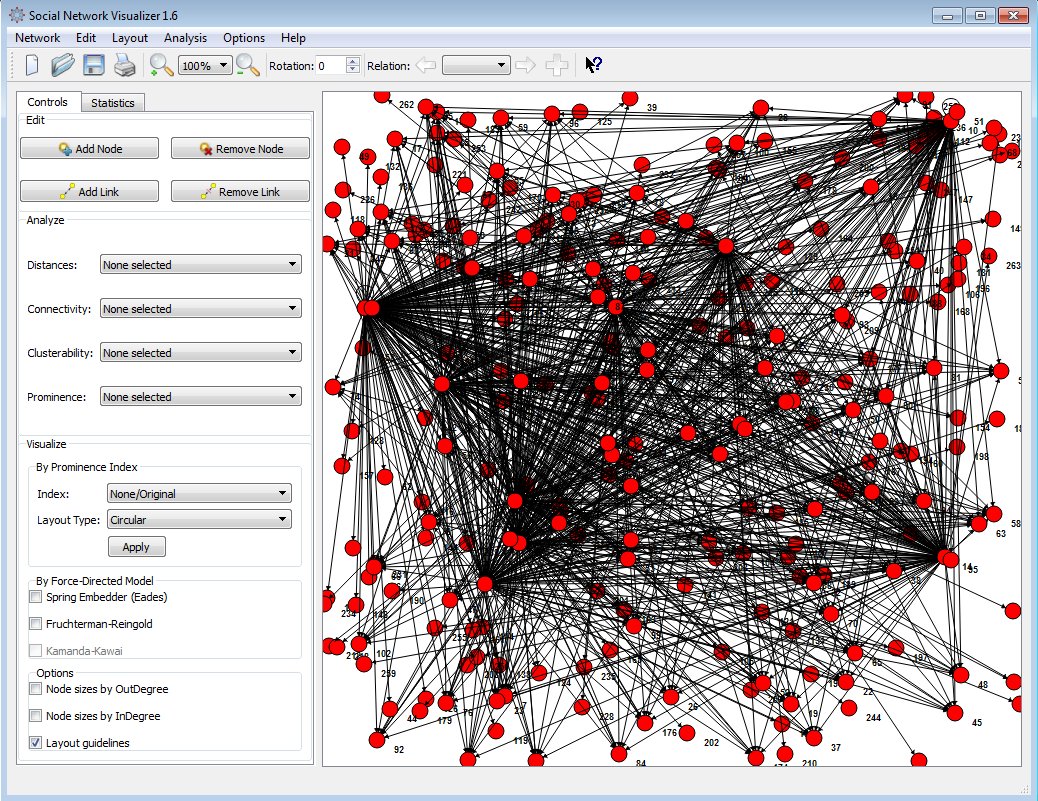
The process is multithreaded and completes within seconds, even for large sets like 1,000 URLs.
Results
The crawler creates a network of all visited webpages as nodes and their links as edges. By default, node sizes are proportional to their outDegree, making patterns visible immediately.
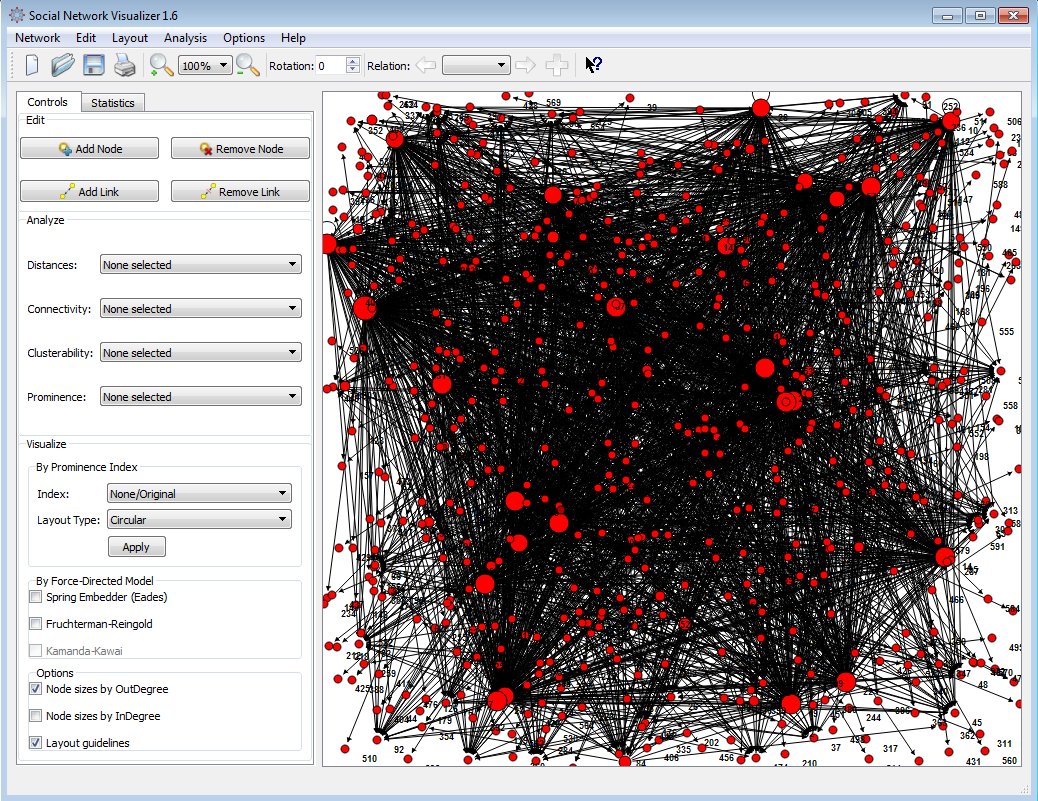
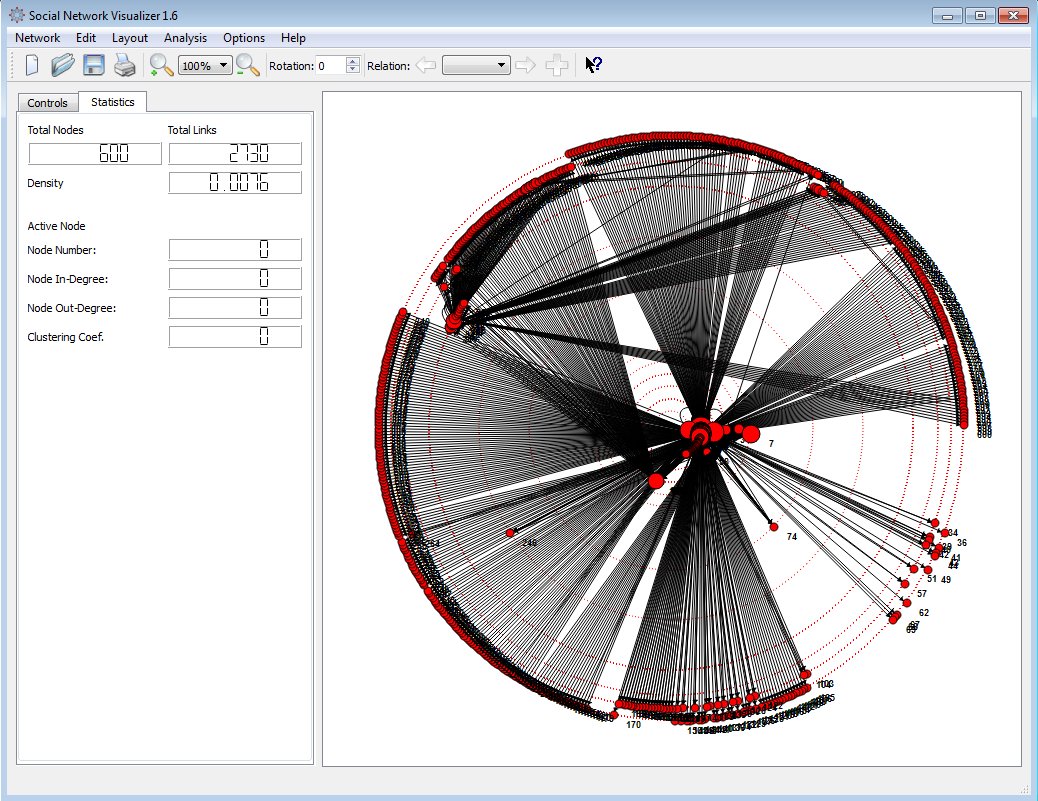
From there, you can analyze the network using the SNA tools provided by SocNetV.
Note: The parser searches for
hreflinks only in the body section of the HTML.
Explore and analyze networks effortlessly with the enhanced capabilities of SocNetV v1.6!